


Documentation - Charts Rebuild
Overview
At Loz Analytics, we built a crucial data pipeline to support an aviation mapping project. Our partner company needed real-time data updates for their mapping software, aiming to reduce time, cost, and eliminate human error. We created a custom data extraction method and developed a multi-step data cleansing, transformation, and feature engineering process entirely in the cloud.
Using Amazon Web Services (AWS), a leading cloud platform, we built a fully scalable and serverless solution for automating processes. AWS Lambda allowed us to run code without provisioning servers, automating key functions in the pipeline. To manage and coordinate these processes across different services, we utilized AWS Step Functions, which orchestrated the entire workflow, ensuring seamless execution and integration of each step.
Additionally, we optimized a complex geospatial query using the Uber H3 package, allowing us to compute distances and relationships between millions of geospatial locations with hex-bin aggregations. This resulted in a fifty-fold reduction in processing time compared to calculating these relationships individually. The pipeline transformed raw data into operationally-ready data for map creators.
Technical Overview
There were six main steps in our process:
- Extract the data from OneDrive / SharePoint and add to AWS S3
- Convert the proprietary data into usable relational data
- Transformation and cleaning
- Feature engineering
- Geospatial indexing with H3
- Orchestration with Lambda and Step Functions
The extraction of data from OneDrive and SharePoint to AWS was more challenging and time-consuming than expected due to firewall constraints and security concerns. Once that was resolved, we built nine modular Python Lambda functions with custom triggers in EventBridge. To handle the transformation steps, we used several S3 directories as temporary storage, avoiding limitations on size and data type when passing data between Lambdas. For simplicity, we used individual Lambda layers over containers, as we only required a few custom packages, such as Uber’s H3 package.
One crucial element of the process was that the Lambdas had to be executed in the correct order, four sequentially, four in parallel and then a final lambda that builds a geospatial index. A Step Function State Machine made this very easy to orchestrate and control the state of the run so that everything is run at the proper time. We use custom triggers through Event Bridge to determine when certain operations should run. This creates a system that is traceable and scalable, describing faults at any given point and produces thorough logs. The below image is the diagram of the Lambdas as they are executed.
State Machine Diagram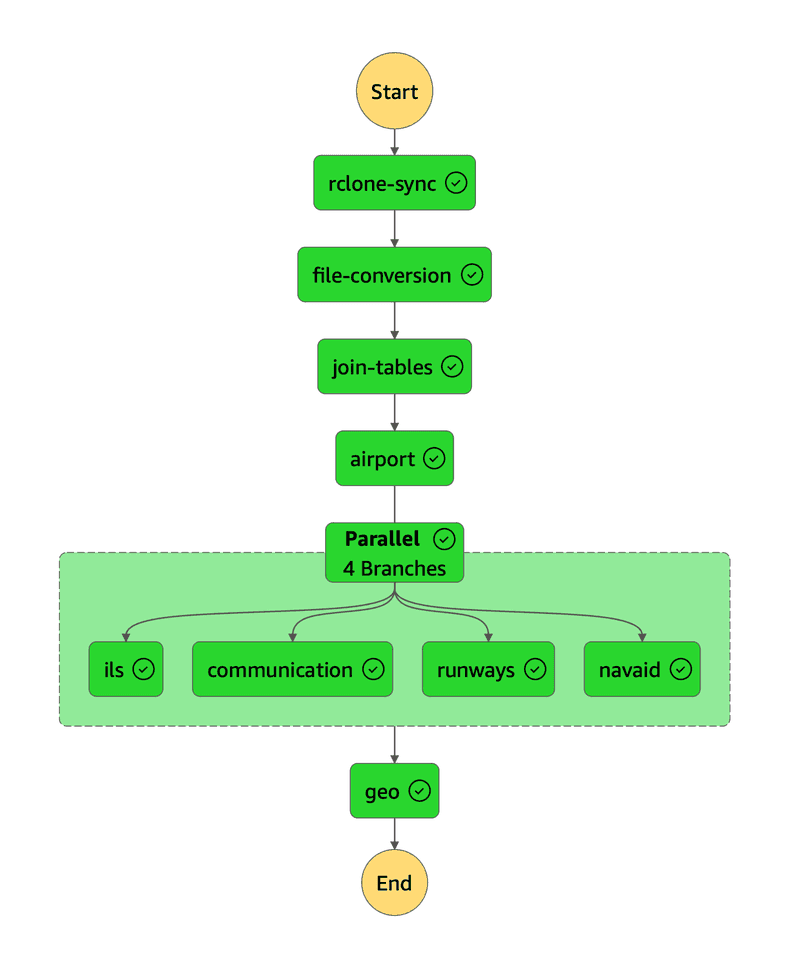
Features
- Each AWS Lambda function conducts only one major task to ensure a more fault tolerant and robust system architecture.
- Granting AWS Lambda and the State Machine the exact IAM roles and permissions needed fulfilled the "least privilege" best security practice.
- Rebuilding the geospatial index using H3 resulted in a fifty-fold reduction of processing time.
- Unit tests ensure that the data is pristine and operational at all times.
Cost Efficiency
By transitioning to AWS Lambda, we made significant improvements on cost. AWS Lambda pricing is very low cost (as an example, currently $0.20 per million invocations), and as a serverless offering, is low maintenance. Because this pipeline is fully automated, all manual labor is eliminated, saving about eight hours per week. The previous system of notifying every operator that they need to download the new data (which is easy to miss) was burdensome, and our system eliminated this issue.
Future Planning & Considerations
This data rebuild project was successful, but there were numerous issues along the way, primarily with syncing the data between OneDrive and AWS S3. Access to this data will speed tool performance and give leadership more control over when the data is gathered and synced, permitting developers to focus on designing new tools. Otherwise, our team at Loz continues to get more proficient at orchestrating complex workflows within AWS Lambda.
Some final considerations:
- Research and carefully weigh the pros and cons of using open source Lambda templates and pre-built layers. If the code or libraries are out of date, untangling the web of issues can be a difficult task. Sometimes the issues aren’t immediately evident.
- If you can use native functionality, do that over custom libraries.
- The transition of developing the functionality locally and then moving to Lambda is not always a perfect ‘lift and shift’.
- Conduct a holistic pricing strategy - what is the actual cost of human error, address long-term maintenance and ease of use.